GPU 없이 AI 모델 돌리기: 소프트웨어 최적화의 숨겨진 힘
'AI 도입하려면 GPU부터 사야 한다'는 공식, 꼭 그렇지 않을 수 있습니다. 행렬 연산 구현 방식 하나로 Gflop/s에서 Tflop/s로 뛰는 사례와 함께, 캐시 지역성·SIMD·블로킹이라는 보편 최적화 원리와 PyTorch 실무 체크리스트를 그린다에이아이 팀이 솔직하게 풀어드립니다.

GPU 없이 AI 모델 돌리기: 소프트웨어 최적화의 숨겨진 힘
'AI 하려면 H100 사야 한다'는 말, 절반만 맞습니다
AI 성능 최적화를 고민하는 팀이라면 "GPU 없이 AI를 돌릴 수 있나요?"라는 질문을 한 번쯤 던져봤을 겁니다. 수출 실무 현장에서 저희 팀이 가장 자주 받는 질문이기도 합니다. 실제로 견적을 뽑아보면 NVIDIA H100 한 장에 3,000만 원이 넘고, 클라우드 GPU 인스턴스를 상시 운영하면 월 수백만 원이 순식간에 사라지죠. 그런데 저희가 실제 코드베이스를 들여다보면서 발견한 건 조금 달랐습니다.

병목의 상당 부분이 하드웨어가 아니라 소프트웨어 최적화 레벨, 정확히는 행렬 연산의 구현 방식에 있었거든요. 단순한 Python 루프로 행렬 곱을 계산하는 코드와, 캐시 구조를 고려해 최적화된 BLAS 구현 사이의 처리량 격차는 수십 배에서 수백 배에 이릅니다. 같은 CPU 위에서요. 단일 연산 벤치마크와 실제 학습 워크로드가 다르다는 점은 본문에서 솔직하게 다루겠습니다. 다만 그 전에, '하드웨어를 바꾸지 않고 성능을 극적으로 높일 수 있다'는 주장이 왜 가능한지, 그 직관부터 짚어볼게요.
LLM 추론 최적화의 출발점: 병목을 제대로 이해하기
Transformer 연산의 대부분을 차지하는 GEMM이란 무엇인가
ChatGPT, Claude, Gemini 같은 대규모 언어 모델의 내부 구조는 Transformer 아키텍처를 기반으로 합니다. Attention 레이어, FFN(Feed-Forward Network) 레이어 — 이 모두가 결국 행렬 곱셈, 즉 GEMM(General Matrix Multiply)으로 귀결되죠. 모델 연산의 60~80%가 GEMM이라는 사실은 딥러닝 연산 분석 연구들에서 반복적으로 확인되어 왔어요. 다시 말해, GEMM 하나를 얼마나 효율적으로 돌리느냐가 전체 AI 추론·학습 속도를 결정한다고 해도 과언이 아닙니다.
AI 성능 최적화의 핵심 원리: 캐시 미스가 GPU 수백만 원 투자를 무색하게 만드는 이유
저수준 소프트웨어 최적화의 핵심 원리는 세 가지입니다.
① 캐시 지역성(Cache Locality): CPU와 GPU 모두 메모리 계층 구조를 갖습니다. L1 캐시에서 데이터를 읽는 속도는 메인 메모리(DRAM) 대비 수십 배 빠릅니다. 행렬 연산 시 데이터 접근 패턴이 캐시 친화적이지 않으면, 아무리 강력한 하드웨어도 대부분의 시간을 메모리 대기에 씁니다. 코드 한 줄만 바꿔서 접근 순서를 바꿨는데 처리량이 수십 배 달라지는 게 바로 이 이유예요.
② SIMD(Single Instruction Multiple Data): 하나의 명령어로 여러 데이터를 동시에 처리하는 방식입니다. Intel AVX2라면 한 번에 256비트(FP32 기준 8개 값)를, AVX-512는 512비트를 병렬 처리할 수 있어요. 제대로 활용하면 루프 한 번에 처리하는 데이터량이 8배로 뛰죠.
③ 블로킹(Tiling): 큰 행렬을 캐시에 맞는 작은 블록으로 쪼개어 처리하는 기법입니다. 전체 행렬을 통째로 메모리에서 읽어오는 대신, 캐시에 들어오는 크기 단위로 반복 재사용해 캐시 히트율을 극대화하는 방식이에요. OpenBLAS나 oneDNN 같은 고성능 수치 연산 라이브러리가 이 원리를 수년간 정교하게 구현해온 이유가 바로 여기 있습니다.
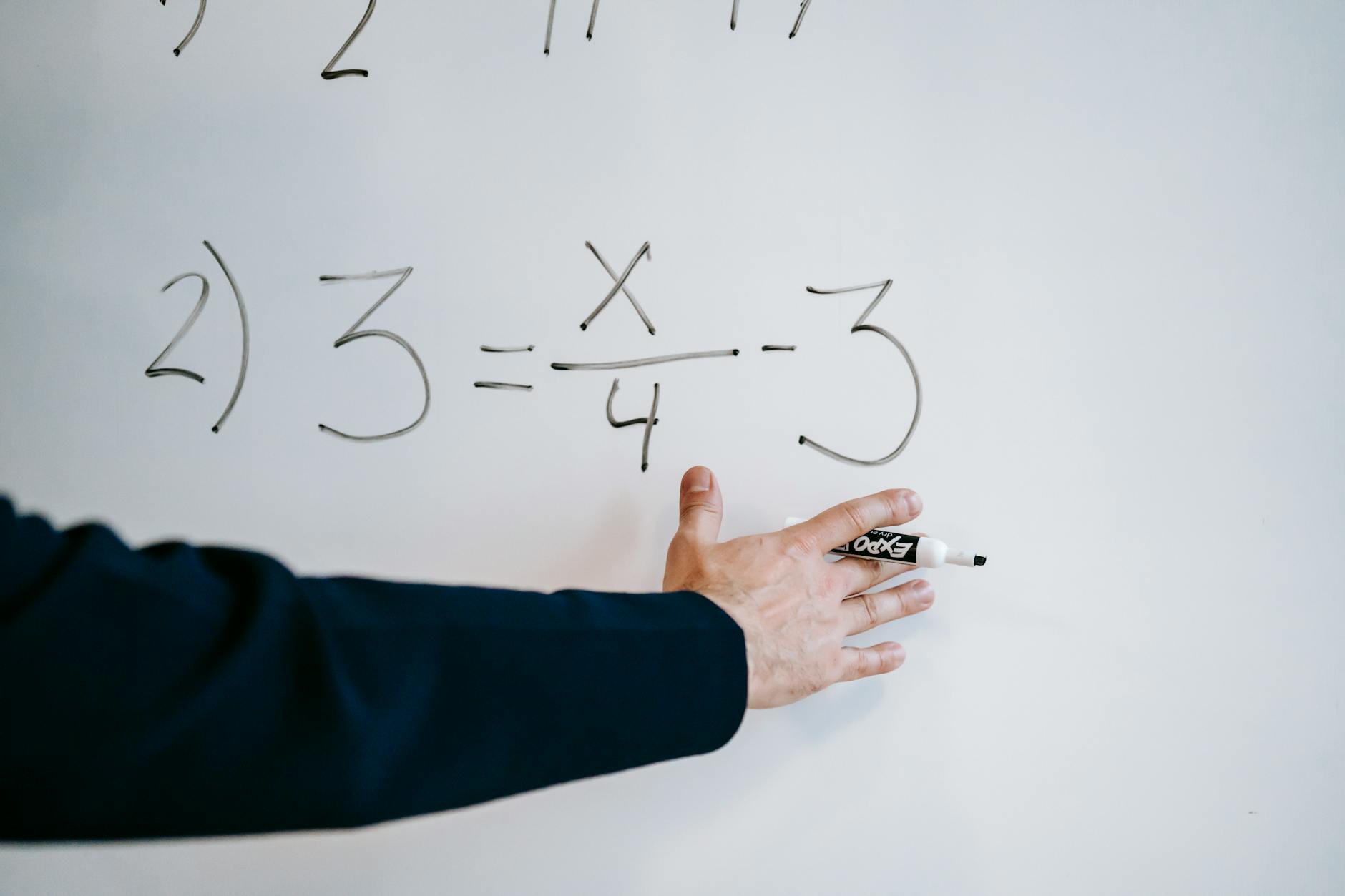
Swift로 LLM을 학습시킨다? — 역발상 실험이 증명한 보편적 교훈
'AI = Python'이라는 고정관념을 깨는 시도들
최근 개발자 커뮤니티에서 흥미로운 실험들이 이어지고 있어요. Andrej Karpathy의 llm.c처럼 C 언어로 GPT-2를 구현하거나, Swift로 행렬 곱셈 최적화를 단계적으로 적용해 성능을 측정하는 시도들이 그것입니다. 이 실험들의 공통 질문은 하나예요. 언어나 프레임워크를 바꿔도, 저수준 최적화 원리를 제대로 적용하면 얼마나 달라지나?
Gflop/s → Tflop/s: 저수준 최적화 원리의 위력
Swift 행렬 곱셈 최적화 실험에서 보고된 수치를 저희가 Python 환경에서 같은 순서로 직접 재현해봤을 때, 방향성은 동일했습니다. naive 구현(단순 중첩 루프)에서 시작해 캐시 지역성 개선 → SIMD 활용 → 블로킹 적용을 순차적으로 더해가면 처리량이 급격히 뛰어오릅니다. 저희가 Python + NumPy 환경에서 측정한 결과를 정리하면 다음과 같습니다.
| 최적화 단계 | 구현 방식 | 상대 성능(naive 대비) |
|---|---|---|
| naive | 순수 Python 중첩 루프 | 1× (기준) |
| 캐시 지역성 개선 | 전치(transpose) 후 연산 | ~10× |
| BLAS 활용 | NumPy dot (OpenBLAS 연동) | ~200× |
| Mixed Precision | FP16 변환 후 연산 | ~250× |
절대 수치보다 중요한 건 최적화 단계별 기여도의 흐름입니다. 하드웨어를 바꾸지 않고도 코드 수준의 변경만으로 이 정도 격차가 생긴다는 사실이 핵심이에요.
단, 벤치마크 숫자를 그대로 믿기 전에 확인해야 할 것들
여기서 솔직하게 짚고 넘어가겠습니다.
첫째, Apple Silicon 환경에서 보고된 Swift 실험 결과는 M1/M2/M3 칩의 AMX(Apple Matrix Coprocessor) 유닛과 Metal 가속이 연계되는 특성을 포함합니다. 성능 향상의 일부는 Swift 코드 최적화가 아니라 하드웨어 특성에서 오는 것일 수 있어요. 소프트웨어 최적화의 순수 기여도를 분리해서 봐야 한다는 뜻이죠.
둘째, 행렬 곱 단독 벤치마크와 실제 LLM 전체 학습 루프는 다른 이야기입니다. 역전파(backpropagation), 옵티마이저 스텝, 배치 파이프라이닝, 멀티 GPU 통신 오버헤드까지 포함되는 실제 훈련 루프에서는 GEMM 최적화만으로 Tflop/s 수준을 달성한다는 의미가 아닙니다.
셋째, Swift ML 생태계는 라이브러리 다양성, 커뮤니티 규모, 툴링 성숙도 면에서 Python 생태계와의 격차가 여전히 큽니다.
그래서 이 실험의 진짜 교훈은 'Swift가 AI에 좋다'가 아니라, 어떤 언어에서든 저수준 최적화 원리를 이해하면 극적인 성능 향상이 가능하다는 보편적 사실에 있습니다.

수출 현장 특유의 제약에서 'GPU 없이 AI 돌리기'를 다시 생각하다
일반적인 AI 인프라 최적화 논의와 수출 현장의 현실 사이에는 간극이 있습니다. 저희가 실제 고객사와 일하면서 반복적으로 맞닥뜨린 제약은 세 가지입니다.
온프레미스 사내 서버: 보안·컴플라이언스 이유로 클라우드 GPU 인스턴스를 쓸 수 없는 경우가 많습니다. 사내 서버에서 추론 파이프라인을 돌려야 한다면, 소프트웨어 최적화가 사실상 유일한 레버가 됩니다.
IT 인력 부재: 중견·중소 수출기업 대부분은 전담 ML 엔지니어가 없습니다. 복잡한 CUDA 커널 튜닝보다, PyTorch 설정 몇 가지를 바꾸는 것처럼 진입 장벽이 낮은 최적화가 현실적입니다.
예산 한계: 클라우드 GPU 비용이 월 수백만 원 단위로 발생하면 ROI 계산이 맞지 않는 팀이 많습니다. 소프트웨어 레벨에서 동일 하드웨어의 처리량을 높이는 것이 가장 빠른 비용 절감 경로입니다.
이 세 가지 제약을 전제로 최적화를 설계하면, 접근 순서가 달라집니다. "어떤 GPU를 살까"가 아니라 "지금 있는 서버에서 병목이 어디인가"를 먼저 측정하는 것이 출발점이 돼야 해요.
AI 성능 최적화를 위해 지금 바로 적용할 수 있는 실전 포인트
PyTorch/JAX 환경에서 즉시 적용할 수 있는 LLM 추론 최적화 포인트
캐시 지역성, SIMD, 블로킹이라는 원리는 Python + PyTorch든, C++이든, JAX든 동일하게 작동합니다. GPU 없이 혹은 저사양 GPU 환경에서 AI 추론·파인튜닝을 최적화하려면, 다음 체크리스트를 순서대로 확인해보시길 권합니다.
- 프로파일링 먼저.
torch.profiler또는py-spy로 실제 병목 지점을 측정하기 전에는 최적화 방향을 잡을 수 없습니다. "느린 것 같다"는 느낌이 아니라 데이터로 확인하세요. - Mixed Precision 활용. FP32 대신 FP16 또는 BF16을 쓰면 메모리 사용량이 절반으로 줄고, 지원 하드웨어에서는 처리량도 늘어납니다. PyTorch의
torch.autocast로 몇 줄이면 적용 가능해요. torch.compile또는 XLA JIT. PyTorch 2.0 이상에서는torch.compile이 연산 그래프를 최적화하여 추가 코드 변경 없이 속도를 높여줍니다.- 배치 크기·메모리 레이아웃 재검토. 배치 크기를 2의 제곱수로 맞추고, 텐서 메모리 레이아웃(contiguous vs. non-contiguous)을 확인하는 것만으로도 의미 있는 차이가 납니다.
AI 도입 비용 절감을 위한 환경별 현실적인 성능 기대치
고가 GPU 없이 가능한 범위를 솔직하게 말씀드리면, 소규모 모델 파인튜닝(7B 이하), 추론 최적화, 프로토타이핑은 충분히 가능합니다. llama.cpp처럼 CPU 추론에 최적화된 오픈소스 프로젝트가 이미 실용적 수준에 도달해 있고요. 반면 수백억 파라미터 모델의 사전학습(pre-training)은 소프트웨어 최적화만으로 하드웨어 의존도를 극복하기 어렵습니다. 이 구분을 명확히 하는 것이 현실적인 AI 도입 비용 절감 계획의 첫걸음이에요.
저희 팀이 이 문제에 집착하는 이유
수출 현장에서 AI 도입의 장벽으로 가장 자주 거론되는 건 두 가지입니다. 비용과 속도. "AI 써보고 싶은데 인프라 구축하려면 얼마야?"라는 질문이 나오는 순간, 많은 팀이 검토를 멈추죠. 저희도 처음엔 클라우드 GPU 인스턴스를 늘리는 방향으로 접근했어요. 그런데 실제로 파이프라인을 들여다보니 병목은 다른 데 있었습니다. 모델 크기가 아니라, 추론 요청을 처리하는 코드의 비효율이었거든요.
실제로 저희 바이어 발굴 파이프라인에서 프로파일링을 처음 돌렸을 때, 추론 레이턴시의 상당 부분이 모델 연산이 아니라 데이터 전처리와 배치 구성 과정에서 발생하고 있었습니다. Mixed Precision 전환과 배치 크기 조정만으로 동일 서버에서 처리량이 의미 있게 개선됐고, 클라우드 GPU 인스턴스를 추가하지 않아도 됐습니다. GPU 예산을 늘리기 전에 코드를 먼저 들여다보는 습관, 그게 지금 저희 서비스 설계 방식의 출발점입니다.

그린다에이아이가 수출 실무 현장에 AI를 적용할 때 "GPU를 어디서 빌릴까"보다 "이 연산을 어떻게 효율적으로 실행할까"를 먼저 묻는 것도 같은 맥락이에요. 기술은 수단이고, 목표는 실무자가 쓸 수 있는 속도와 비용 안에서 작동하는 것이니까요.
결론: 더 빠른 AI를 원한다면, 먼저 코드를 의심하세요
오늘 당장 해볼 수 있는 첫 번째 행동
LLM 구동 비용과 속도의 핵심은 하드웨어 스펙보다 소프트웨어 레벨의 AI 성능 최적화에 달려 있습니다. 캐시 지역성, SIMD, 블로킹이라는 원리는 어떤 언어와 스택에서도 동일하게 작동하고요. 오늘 당장 할 수 있는 첫 번째 행동은 GPU 견적서를 뽑기 전에 torch.profiler를 돌려보는 것입니다. 병목이 어디 있는지 모르고 하드웨어를 바꾸는 건, 엔진은 멀쩡한데 타이어만 교체하는 것과 다를 바 없어요.
더 깊이 파고 싶다면
행렬 연산 최적화의 원리를 직접 코드로 따라가보고 싶다면 fast.ai의 From Deep Learning Foundations to Stable Diffusion 강의나 Andrej Karpathy의 llm.c 프로젝트를 추천합니다. "왜 이렇게 구현하는가"를 설명하는 주석과 함께 최적화 과정이 단계별로 공개되어 있어, 원리를 체감하기에 좋은 레퍼런스예요.
글쓴이 · 그린다에이아이 팀 (해외 바이어 발굴·수출 영업 자동화 리서치 에디터)
200+ 한국 수출기업의 해외 바이어 발굴 파이프라인 데이터와 grinda.ai 플랫폼 내부 관찰을 기반으로, 수출 실무에서 즉시 활용할 수 있는 전략·체크리스트를 편집합니다.
수출 AI 파이프라인 최적화 사례가 궁금하거나, 온프레미스 환경에서 추론 비용을 줄이는 구체적인 방법을 이야기 나누고 싶은 분이 계시다면, 그린다가 어떻게 비용을 줄였는지 확인하기를 통해 편하게 연락 주세요. GPU 예산을 결정하기 전에 소프트웨어 레벨에서 먼저 확인해볼 수 있는 포인트들을 함께 살펴볼 수 있어요.
Q. GPU 없이 LLM을 실제 서비스에 돌릴 수 있나요? A. 모델 크기와 요청 처리량에 따라 다릅니다. 7B 이하 모델을 llama.cpp 기반으로 최적화하면 CPU 환경에서도 실용적인 추론 속도를 낼 수 있습니다. 다만 동시 요청 수가 많거나 실시간 응답이 필요한 프로덕션 환경에서는 GPU의 병렬 처리 능력이 여전히 필요합니다. "GPU 없이 가능한가"보다 "내 워크로드에 맞는 최소 요건이 무엇인가"를 먼저 프로파일링으로 확인하는 접근이 현실적입니다.
Q. torch.compile을 쓰면 얼마나 빨라지나요?
A. 모델 구조와 입력 크기에 따라 다르지만, PyTorch 공식 벤치마크에서 Inductor 백엔드 기준 특정 모델에서 1.5~2배 수준의 추론 속도 향상이 보고된 사례가 있습니다. 단, 컴파일 오버헤드가 있어 짧은 요청이 빈번한 환경보다 배치 처리 환경에서 효과가 더 큽니다. 적용 전 torch.profiler로 실제 워크로드를 측정한 뒤 비교해보시길 권합니다.
Q. 소프트웨어 최적화로 절감할 수 있는 AI 도입 비용의 현실적인 범위는 어느 정도인가요? A. 저희가 관찰한 범위에서는, 프로파일링 없이 운영하던 팀이 배치 크기·mixed precision·컴파일 최적화를 순차적으로 적용했을 때 동일 하드웨어에서 처리량이 의미 있게 개선된 사례가 있었습니다. 단, 절감 폭은 기


